
Mysql主从复制
MYSQL_主从复制
MySQL主从复制_ST Cp的博客-CSDN博客_mysql主从复制
MySQL主从复制_张三疯学独孤九剑的博客-CSDN博客_mysql主从复制
MysQL主从复制是一个异步的复制过程,底层是基于Mysql数据库自带的二进制日志功能。就是一台或多台MySQL数据 库(slave,即从库)从另一合MySQL 数据库(master,即主库)进行日志的复制然后再解析日志并应用到自身,最 终实现从库的数据和主库的数据保持一致。MysQL主从复制是MysQL数据库自带功能,无需借助第三方工具。
原理剖析
三个线程
实际上主从同步的原理就是基于binlog进行数据同步的。在主从复制过程中,会基于3个线程来操作,一个主库线程,两个从库线程。
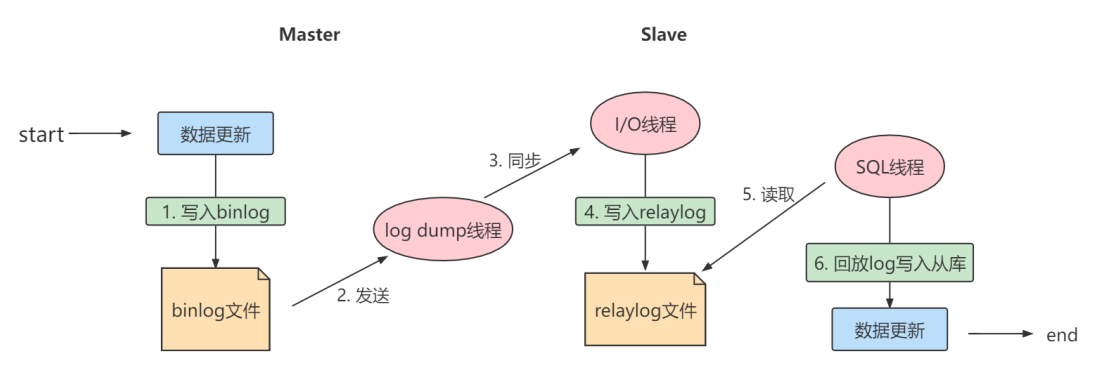
二进制日志转储线程(Binlog dump thread)是一个主库线程。当从库线程连接的时候, 主库可以将二进
制日志发送给从库,当主库读取事件(Event)的时候,会在 Binlog 上加锁,读取完成之后,再将锁释
放掉。
从库 I/O 线程会连接到主库,向主库发送请求更新 Binlog。这时从库的 I/O 线程就可以读取到主库的
二进制日志转储线程发送的 Binlog 更新部分,并且拷贝到本地的中继日志 (Relay log)。
从库 SQL 线程会读取从库中的中继日志,并且执行日志中的事件,将从库中的数据与主库保持同步。
MySQL复制过程分成三步:
- master将改变记录到二进制日志 (binary log)
- slave将master的binary 1og拷贝到它的中继日志 (relay log)
- slave重做中继日志中的事件,将改变应用到自己的数据库中
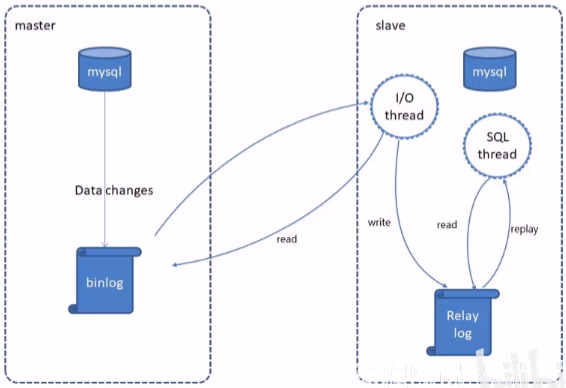
复制原理:
Mysql 中有一种日志叫做 bin 日志(二进制日志)。这个日志会记录下所有修改了数据库的SQL 语句(insert,update,delete,create/alter/drop table, grant 等等)。
主从复制的原理其实就是把主服务器上的 bin 日志复制到从服务器上执行一遍,这样从服务器上的数据就和主服务器上的数据相同了。
复制过程
- 主节点必须启用二进制日志,记录任何修改了数据库数据的事件。
- 从节点开启一个线程(I/O Thread)把自己扮演成 mysql 的客户端,通过 mysql 协议,请求主节点的二进制日志文件中的事件
- 主节点启动一个线程(dump Thread),检查自己二进制日志中的事件,跟对方请求的位置对比,如果不带请求位置参数,则主节点就会从第一个日志文件中的第一个事件一个一个发送给从节点。
- 从节点接收到主节点发送过来的数据把它放置到中继日志(Relay log)文件中。并记录该次请求到主节点的具体哪一个二进制日志文件内部的哪一个位置(主节点中的二进制文件会有多个,在后面详细讲解)。
- 从节点启动另外一个线程(sql Thread ),把 Relay log 中的事件读取出来,并在本地再执行一次。
mysql的主从复制
需要至少两台以上服务器来创建数据库,主从复制可以是一主一从,也可以是一主多从
在linux虚拟机上分别配置两台mysql数据库
在虚拟机安装MySQL详解_小婷学习日记的博客-CSDN博客_虚拟机部署mysql
介绍
配置-主库Master
第一步 :修改mysql数据库主库配置文件 vim /etc/my.cnf
1 | [mysqld] |
第二步:重启Mysql服务
1 | systemctl restart mysqld |
第三步:登录mysql数据库新建权限用户
登录Mysql数据库,执行下面SQL
1 | GRANT REPLICATION SLAVE ON ** to 'xiaoming'@'%' identified by 'Root@123456'; |
用户名称和密码并不是固定
注:上面SQL的作用是创建一个用户xiaoming,密码为ROot@123456,并且给xiaoming用户授予REPLICATION SLAVE 权限。常用于建立复制时所需要用到的用户权限,也就是slave必须被master授权具有该权限的用户,才能通过该用户复制
第四步:执行sql,记录下结果中file和position的值
1 | show master status |
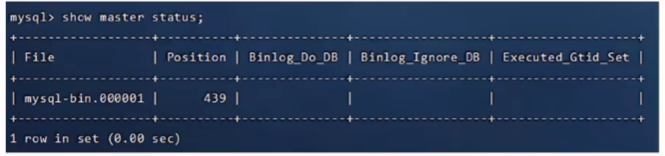
注:上面的SQL的作用是查看master的状态,执行完SQL后不要再执行任何操作
配置-从库slave
第一步:修改mysql数据库从库配置文件 vim /etc/my.cnf
1 | [mysqld] |
第二步:重启Mysql服务
1 | systemctl restart mysqld |
第三步:登录Mysql数据库,执行下面SQL
1 | # host 是主库的ip地址,用刚才在主库创建的权限用户登录master_user |
第四步:查看从库的状态
1 | show slave status |
读写分离
在主数据库中进行增删查改操作,从数据库会复制相应的操作内容
主数据库进行读写操作,从数据库只能进行读操作,不能进行写操作
面对日益增加的系统访问量,数据库的吞吐量面临若巨大瓶颈。对于同一时刻有大量并发读操作和较少写操作类型的 应用系统来说,将数据库拆分为主库和从库,主库负责处理事务性的增利改操作,从库负费处理查询操作,能够有效 的避免由数据更新导致的行锁,使得整个系统的查询性能得到极大的改善.
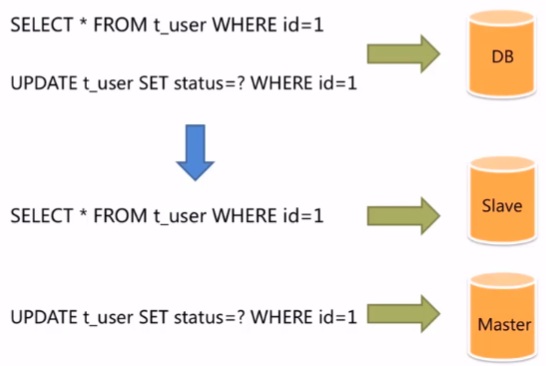
在项目中实现读写分离
Sharding-JDBC介绍
Sharding-JDBC定位为轻量级Java框架,在Java的JDBC层提供的额外服务。它使用客户端直连数据库,以jar包形式 提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容DBC和各种ORM框架。 使用Sharding-]DBC可以在程序中轻松的实现数据库读写分离
- 适用于任何基手JDBC的ORM框架,如:JPA, Hibernate,Mybatis, Spring JDBC Template或直接使用DBC。
- 支持任何第三方的数据库连接池,如:DBCP, C3PO, BonecP, Druid, HikariCP等。
- 支持任意实现DBC规范的数据库。目前支持MySQL, Oracle, SQLServer, PostgreSQL以及任何遵循SQL92标准的数据库
案列
导入配置
1 | <dependency> |
配置主从数据库数据源
在pom文件中配置读写分离的规则
1 | spring: |
在配置文件中配置允许bean定义覆盖配置项
防止druid创建的数据源和引入的Sharding创建数据源发生冲突,配置其能够覆盖
总结
配置完成后,不需要更改项目中的任何代码,即可使用mysql的主从复制,从而提高并发压力和查询速度,当使用到redis缓存的时候,也可以使用redis的主从复制,原理跟mysql的主从复制大致相同,这样可以减少数据库压力也可以减少缓存压力

